
处理数据架构之 SpringBatch(更新:主要流程图,详情见第四章节,详尽的很哦)
1 什么是Spring Batch?
Spring Batch 作为 Spring 的子项目,是一款基于 Spring 的企业批处理框架。通过它可以构建出健壮的企业批处理应用。Spring Batch 不仅提供了统一的读写接口、丰富的任务处理方式、灵活的事务管理及并发处理,同时还支持日志、监控、任务重启与跳过等特性,大大简化了批处理应用开发,将开发人员从复杂的任务配置管理过程中解放出来,使他们可以更多地去关注核心的业务处理过程。
2 为什么采用Spring Batch?
Spring Batch 框架通过提供丰富的即开即用的组件、和高可靠性、高扩展性的能力,可以根据业务需求进行随意扩展 数据读取、写入、以及数据处理方式。其高扩展性为项目带来丰富的处理方案和随意组合能力。
使用Spring Batch不需要多余的组件依赖,仅仅需要MySQL作为任务记录仓库,服务架构轻巧,维护方便,部署简单。
3 技术框架(官网说明)
3.1 Spring批处理分层架构

这种分层的体系结构突出了三个主要的高级组件:应用程序、核心和基础设施。应用程序包含所有批处理作业和开发人员使用Spring batch编写的自定义代码。批处理核心包含启动和控制批处理作业所需的核心运行时类。它包括JobLauncher、Job和Step的实现。Application和Core都构建在公共基础设施之上。应用层和核心层建立在基础架构层之上,基础构架层提供顶层的读接口(ItemReader)、写接口(ItemWriter)、处理接口(ItemProcess)和服务(如RetryTemplate:重试模块。可以被应用层和核心层使用)等。
省略
flow的使用
3.2 任务流程

- JobLauncher:任务启动器。可以理解为程序的入口。
- Job:表示一个具体的任务,一个任务可以包含一个Step,也可以包含多个Step,由任务启动器进行启动。
- Step:一个具体的执行步骤,是任务的具体执行内容,一个Step的执行过程包括读数据(ItemReader)、处理数据(ItemProcessor)、写数据(ItemWriter)。
- JobRepository:批处理任务仓库。用来记录任务状态信息,可以看做是一个数据库的接口。(MySQL存储)
3.3 处理结构
Spring Batch 在其最常见的实现中使用“面向块(chunk)”的处理风格。面向块的处理是指一次读取一个数据并创建在事务边界内写出的“块”。一旦读取的项目数等于提交间隔,整个块由写出 ItemWriter,然后提交事务。

job包含了一个或多个step,还有各种定义的监听器,step的内部具体执行内容是一个个tasklet的执行,每次执行完成后(也即一个chunk执行结束后)再执行新的一个tasklet,tasklet包括了chunk和read,process,writer四部分,chunk控制每一批次read、process、writer处理的数量,每当处理完chunk的数据量后再进行下一次tasklet操作,直到数据read不出数据后结束一个step,结束后如果有下一个step则执行下一个step,否则结束job。
3.4 监听器
Spring Batch提供了多种监听器Listener,用于在任务处理过程中触发我们的逻辑代码。常用的监听器根据粒度从粗到细分别有:Job级别的监听器JobExecutionListener、Step级别的监听器StepExecutionListener、Chunk监听器ChunkListener、ItemReader监听器ItemReadListener、ItemWriter监听器ItemWriteListener和ItemProcessor监听器ItemProcessListener等。
| 监听器 | 具体说明 |
|---|---|
| JobExecutionListener | 在Job开始之前(beforeJob)和之后(aflerJob)触发 |
| StepExecutionListener | 在Step开始之前(beforeStep)和之后(afterStep)触发 |
| ChunkListener | 在 Chunk 开始之前(beforeChunk),之后(afterChunk)和错误后(afterChunkError)触发 |
| ItemReadListener | 在 Read 开始之前(beforeRead),之后(afterRead)和错误后(onReadError)触发 |
| ItemProcessListener | 在 Processor 开始之前(beforeProcess),之后(afterProcess)和错误后(onProcessError)触发 |
| ItemWriterListener | 在 Writer 开始之前(beforeWrite),之后(afterWrite)和错误后(onWriteError)触发 |
3.5 元数据表
SpringBatch使用六张业务表存储了所有的元数据信息(包括Job、Step的实例,上下文,执行器信息,为后续的监控、重启、重试、状态恢复等提供了可能)。
- BATCH_JOB_INSTANCE:作业实例表,用于存放Job的实例信息
- BATCH_JOB_EXECUTION_PARAMS:作业参数表,用于存放每个Job执行时候的参数信息,该参数实际对应Job实例的。
- BATCH_JOB_EXECUTION:作业执行器表,用于存放当前作业的执行信息,比如创建时间,执行开始时间,执行结束时间,执行的那个Job实例,执行状态等。
- BATCH_JOB_EXECUTION_CONTEXT:作业执行上下文表,用于存放作业执行器上下文的信息。
- BATCH_STEP_EXECUTION:作业步执行器表,用于存放每个Step执行器的信息,比如作业步开始执行时间,执行完成时间,执行状态,读写次数,跳过次数等信息。
- BATCH_STEP_EXECUTION_CONTEXT:作业步执行上下文表,用于存放每个作业步上下文的信息。
Spring Batch相关域名词解释:
4 Spring Batch在轻量化平台中的应用
4.1 项目准备
4.1.1 项目maven依赖
compile('org.springframework.boot:spring-boot-starter-batch:2.7.0')
4.1.2 框架存储仓库
需要初始化一个数据库spring_batch指定为spring-batch的执行记录数据库。
CREATE DATABASE spring_batch DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
4.2 主要思路
1、获取任务配置信息,通过web端进行的任务配置。
2、由JobLuncher进行作业提交运行。
3、构建Job,其中包括Step步骤、任务监听器。
4、构建Step,其中包括reader、processor、writer,以及Step监听器、processor监听器、writer监听器、chunk监听器。
5、根据数据源配置信息动态构建reader,reader包括全量、增量两种读取方式。
6、根据任务处理配置信息动态构建DAG形成processor任务处理,进行数据批处理主要步骤。由于Spring Batch的处理框架是批次处理,无法进行全局数据处理。
7、根据任务最终写入信息动态构建writer,writer包括覆盖、更新插入、更新三种写入方式。
4.2.1 任务执行流程图
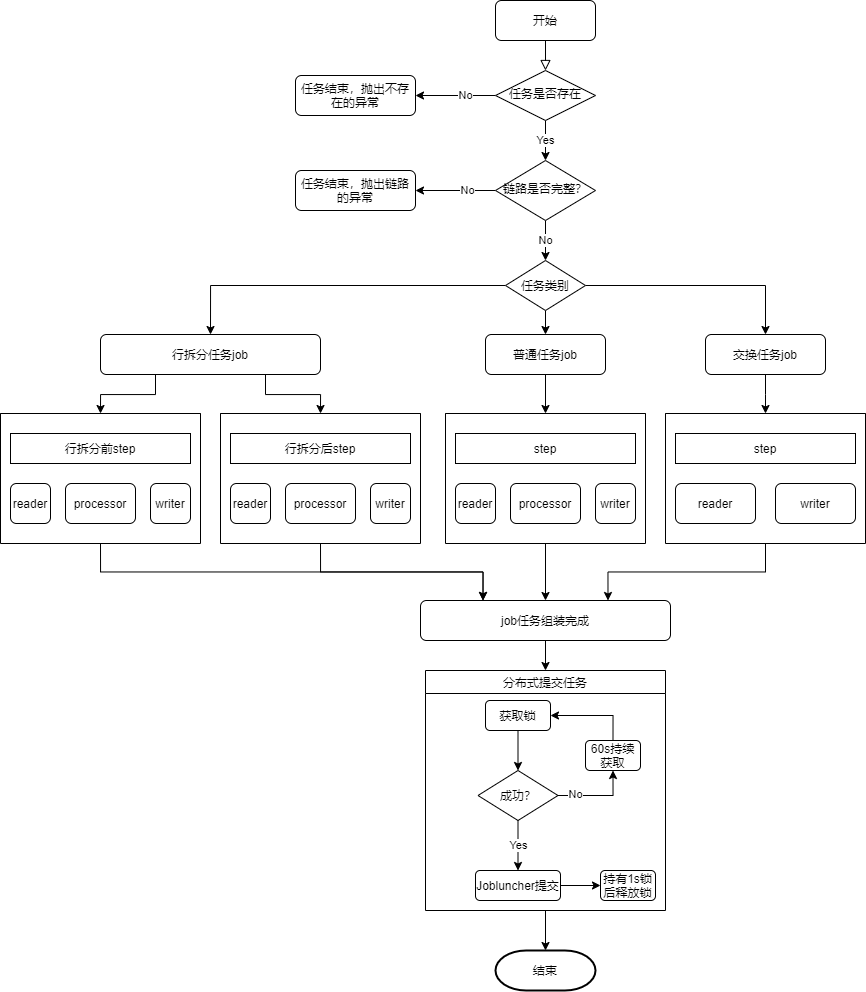
任务执行流程,根据配置信息动态构建Step,采用分布式提交任务的方式,防止进行Spring Batch元数据操作时死锁。
4.2.2 数据读取Reader流程图
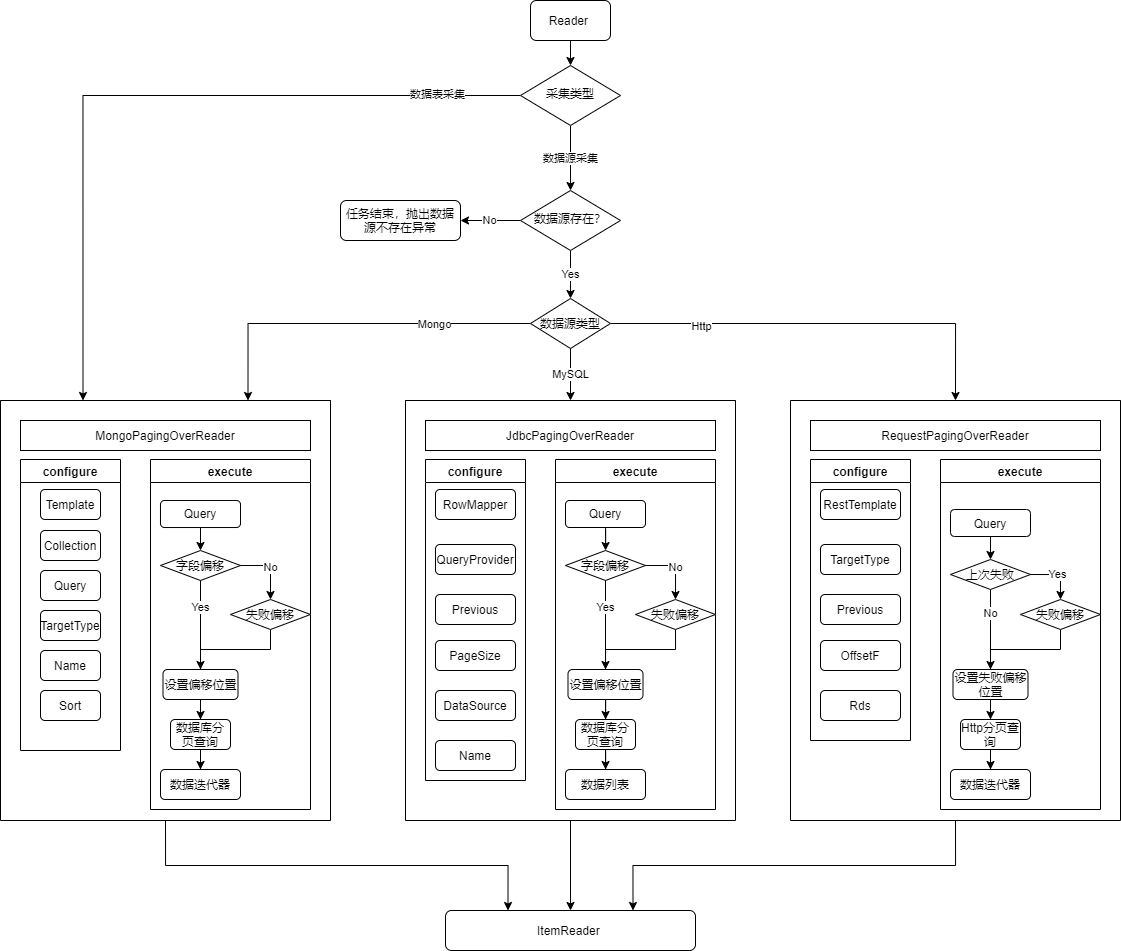
数据读取由读取类型,是否增量决定,Http采集是参考MongoPagingOverReader重写AbstractPaginatedRequestItemReader。
4.2.3 数据处理Processor流程图
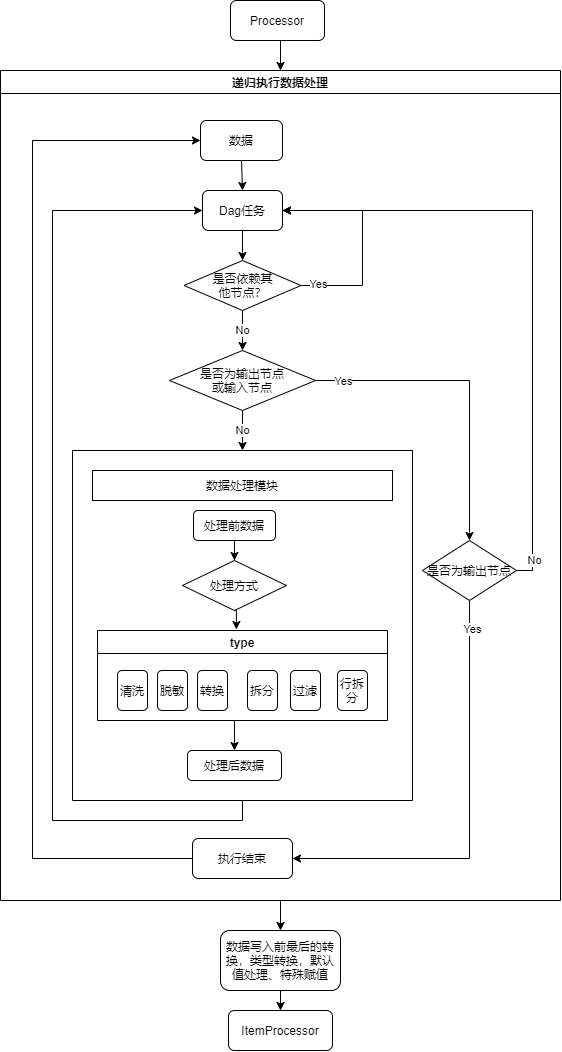
数据处理使用递归处理,遇到输入、采集组件继续,遇到输出组件则停止任务,在进行写入前最后的数据处理。
4.2.4 数据写入Writer流程图
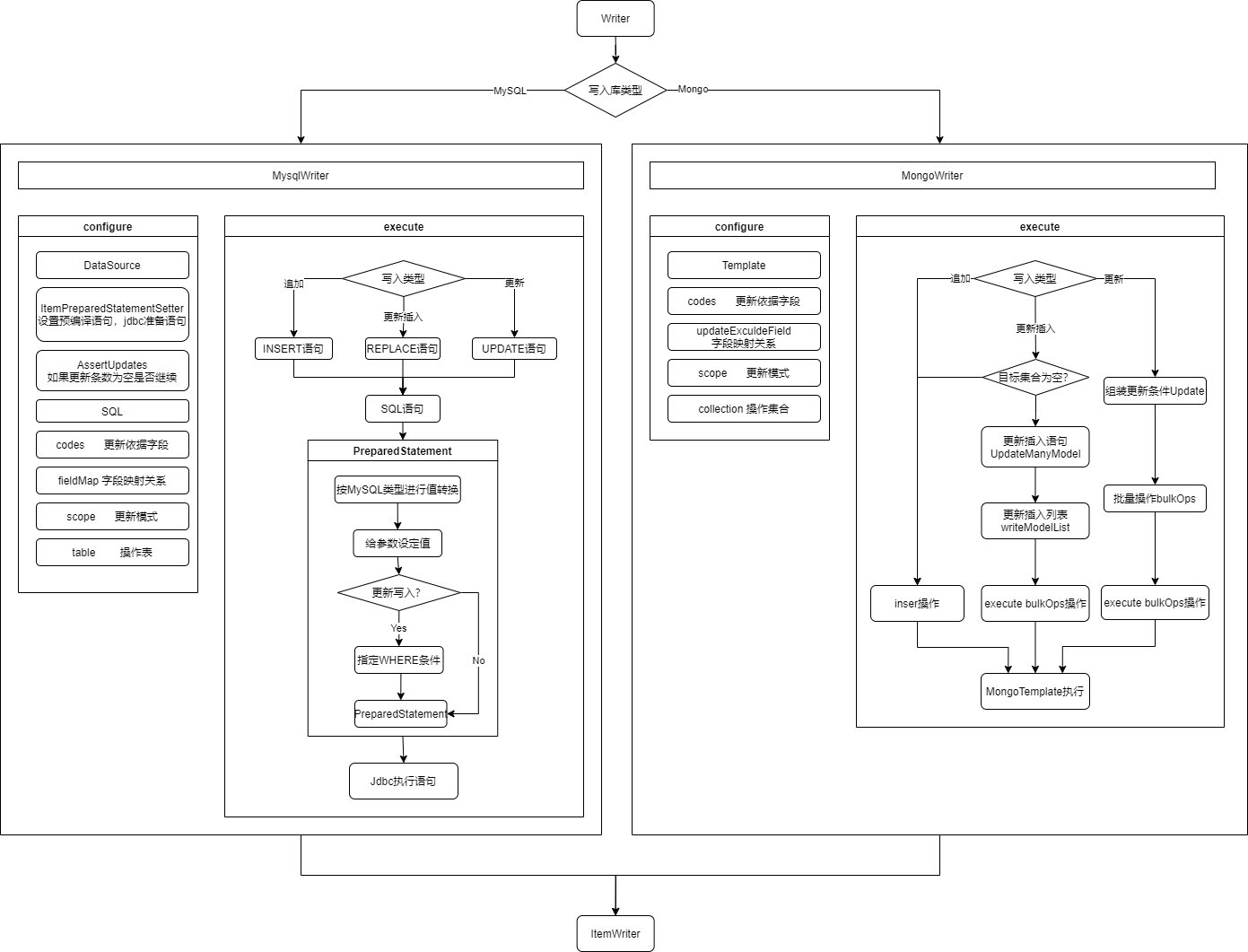
数据写入主要由数据库类型、写入类型进行决定
4.2.5 监听器Listener周期
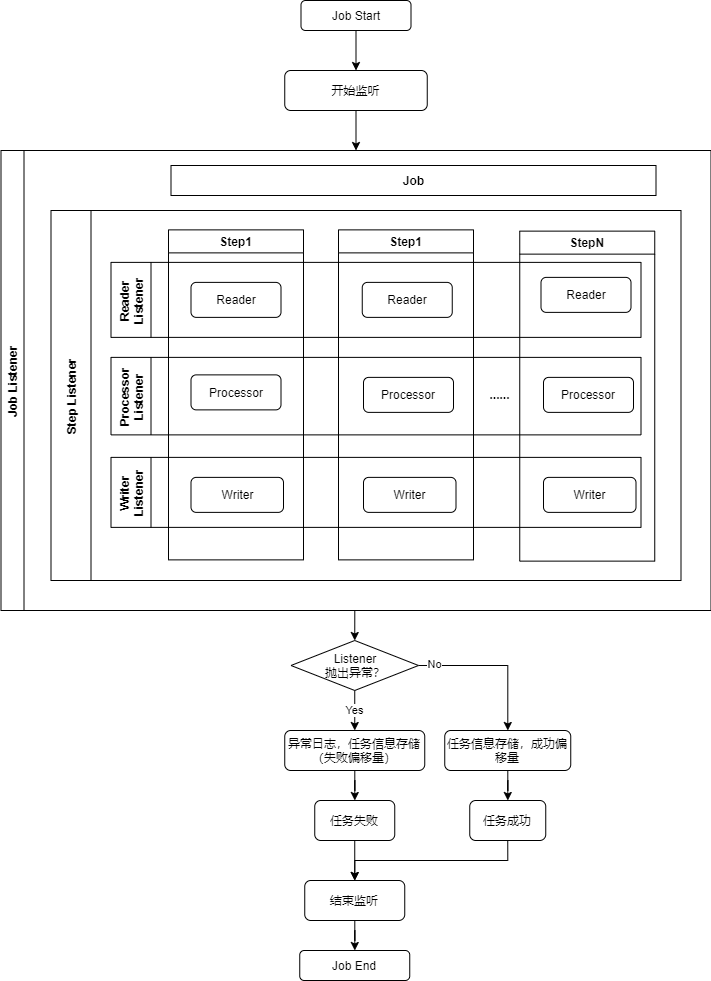
监听器生命周期由任务决定,任务结束,监听器也停止。
5 具体实现方案
5.1 作业提交入口
考虑轻量化平台使用的作业调度为二次开发的xxl-job,会出现高并发情况,在高并发的情况下JobRepository操作任务记录仓库时会出现死锁情况,故采用Redis分布式锁进行作业提交。
private void launcherJobByRedisLock(Job job, JobParameters parameters){ // 防止springbatch同一时间提交任务时获取mysql数据库锁时出现死锁情况增加分布式锁 String key = "spring-batch-job"; boolean flag = false; try { flag = RedisLockUtil.getLockByLua(key, key, 1, 60); if (flag) { JobExecution execution = jobLauncher.run(job, parameters); if (execution.getStatus() == BatchStatus.FAILED) { this.throwables = execution.getAllFailureExceptions(); } } } finally { if (flag) { try { RedisLockUtil.releaseLockByLua(key, key); } catch (IllegalMonitorStateException e) { logger.error("过期释放"); } catch (Exception e) { logger.error("过期释放分布式锁【" + key + "】失败", e); } } } }
job构建的任务信息
parameters可围绕任务整个生命周期的参数信息
5.2 Job构建
在Job构建时设置itemListener监听器以及设置了.preventRestart()不允许重启任务,.incrementer(idIncrementer)是一个自增的id参数作为任务唯一性的标识,因为会有相同的任务在任务调度框架下进行周期性的执行,通过唯一标识防止任务执行重复。
// 单个step public Job jobBuilder(String jobName, RunIdIncrementer idIncrementer, Step step) { return jobBuilderFactory.get(jobName) .incrementer(idIncrementer) .listener(itemListener) .start(step) .preventRestart() .build(); } // 多step public Job jobBuilder(String jobName, RunIdIncrementer idIncrementer, Step step1, Step step2) { return jobBuilderFactory.get(jobName) .incrementer(idIncrementer) .listener(explodeListener) .start(step1).next(step2) .preventRestart() .build(); }
5.3 Step构建
轻量化平台任务执行分为三种,分别是普通任务、行拆分任务、交换任务,普通任务和交换任务一个Step即可完成,行拆分任务则需要两个Step完成。
private void processor() throws Exception { if (task == null) { throw new BizException("任务不存在【" + id + "】"); } List<TaskNodeDTO> nodes = task.getNodes(); if (Boolean.TRUE.equals(task.getDeleted() || nodes == null) || nodes.isEmpty()) { throw new BizException("不存在任务链路【" + id + "】"); } String name = task.getName(); serverLog.debug("Spring-batch>>>>server---->开始构建任务,任务id:{},任务:{}", id, name); RunIdIncrementer runIdIncrementer = new RunIdIncrementer(); JobAndStepBuilderService jobAndStepBuilderService = new JobAndStepBuilderService(logger, (Map<String, Object>) task.getStartAfter()); // 分为交换任务和治理任务 Job job; // 设置任务参数 JobParameters parameters = getJobParameters(name); if (task.getTaskType() == 1) { this.jobName = SnowflakeUtil.prefixUniqueNuber("govern_job_"); List<DagNode> dagNodes = get(nodes); DagNode node = dagNodes.get(0); // todo 去获取dag中是否存在行拆分 if (haveExplore(task.getNodes())) { // 行拆分任务 this.mongoTempTable = SnowflakeUtil.prefixUniqueNuber("springbatch_temp_"); Step toTempMongoStep = jobAndStepBuilderService.toTempMongoStep(node, id, mongoTempTable); Step toDbBuilder = jobAndStepBuilderService.toDbBuilder(node, nodes, id, mongoTempTable); job = jobAndStepBuilderService.jobBuilder(jobName, runIdIncrementer, toTempMongoStep, toDbBuilder); } else { // 普通任务 Step step = jobAndStepBuilderService.stepBuilder(node, id); job = jobAndStepBuilderService.jobBuilder(jobName, runIdIncrementer, step); } } else { // 交换任务 this.jobName = SnowflakeUtil.prefixUniqueNuber("exchange_job_"); ExchangeInputDTO input = exchangeInput(nodes); ExchangeOutputDTO output = exchangeOutput(nodes); Step step = jobAndStepBuilderService.exchangeStep(input, output, id); job = jobAndStepBuilderService.jobBuilder(jobName, runIdIncrementer, step); } // 设置分布式锁提交任务执行 serverLog.debug("Spring-batch>>>>server---->分布式锁提交任务,任务id:{},任务名称:{}", id, name); launcherJobByRedisLock(job, parameters); }
不论需要多少Step,构建单个Step的思路是一致的,不过是根据业务需求进行Step的拆分和构建。
public Step stepBuilder(DagNode dagNode, String jobName) throws Exception { // 获取到dag每个节点任务进行处理,通过同一个process进行处理 Object input = getInput(dagNode); DataOutputDTO output = getOutput(dagNode); StepListener stepListener = new StepListener(logger, jobName); if (COLLECT_DTO.equals(input.getClass().getSimpleName())) { CollectDTO collectDto = (CollectDTO) input; Integer mode = collectDto.getMode(); itemListener.setMode(mode); itemListener.setSource(collectDto.getTable()); stepListener.setMode(mode); } itemListener.setTarget(output.getTableCode()); itemListener.setWriterMode(output.getScope()); ItemReader reader = processorBuilder.readerBuilder(input, startAfter, logger); List<ColumnDTO> cols = output.getCols(); ItemProcessor processor = processorBuilder.processorBuilder(dagNode, cols); MongoItemWriter writer = processorBuilder.writerBuilder(output); TaskletStep step = stepBuilderFactory.get("step") .startLimit(1) .transactionManager(transactionManager) .<Document, Document>chunk(500) .readerIsTransactionalQueue() .reader(reader) .processor(processor) .writer(writer) .listener(new ReaderListener(logger)) .listener(new WirterListener(logger)) .listener(processListener) .listener(itemListener) .build(); step.setStepExecutionListeners(new StepListener[]{stepListener}); return step; }
dagNode任务形成的有向无环图
jobName任务名称
5.3.1 构建Reader
ItemReader reader = processorBuilder.readerBuilder(input, startAfter, logger);
input采集源的信息
startAfter任务每次偏移位置
构建reader的主要结果是返回ItemReader这个接口,processorBuilder.readerBuilder是返回一个实现了ItemReader的reader,processorBuilder.readerBuilder会根据不同input配置信息动态生成reader。
目前根据需求主要支持三种**reader**:
if (MONGO.equalsIgnoreCase(datasourceDO.getType())) { MongoTemplate template = LoadCacheUtil.getMongoTemplate(datasourceDO); return getMongoItemReader(template, dto.getMode(), present, dto.getTable(), offsetF, startAfter); } else if (MYSQL.equalsIgnoreCase(datasourceDO.getType())) { HikariDataSource dataSource = LoadCacheUtil.getConnection(datasourceDO); MysqlReader mysqlReader = new MysqlReader(dto, dataSource, (Map<String, Object>) startAfter); return mysqlReader.getMysqlItemReader(mysqlReader.getMySqlPagingQueryProvider()); } else if (HTTP.equalsIgnoreCase(datasourceDO.getType())) { return getRequestItemReader(startAfter, logger, datasourceDO, offsetF); }
**JdbcPagingOverReader**** **Jdbc类的数据读取,支持增量、全量,失败后偏移位置记录重试
public ItemReader getMysqlItemReader(MysqlPagingQueryOverProvider pagingQueryProvider) throws Exception { JdbcPagingOverReader overReader = new JdbcPagingOverReader(dataSource, pagingQueryProvider, 500); overReader.setRowMapper(new DocumentRowMapper()); overReader.setName("paging-reader"); overReader.setQueryProvider(pagingQueryProvider); overReader.setPrevious(startValue); overReader.setPageSize(500); return overReader; }
**MongoPagingOverReader**** **Mongo类的数据读取,支持增量、全量,失败后偏移位置记录重试
private MongoPagingOverReader getMongoItemReader(MongoTemplate mongoTemplate, Integer mode, String pre, String table, String offsetF, Object startAfter) { MongoPagingOverReader build = new MongoPagingOverReader(); build.setName(PAGING_READER); build.setTargetType(Document.class); build.setTemplate(mongoTemplate); build.setCollection(table); if (mode == 1 && startAfter != null) { build.setPrevious((Map<String, Object>) startAfter); } build.setPageSize(500); build.setQuery(new Query()); if (StringUtils.isNotBlank(offsetF)) { build.setSort(Collections.singletonMap(offsetF, Sort.Direction.ASC)); } else { build.setSort(Collections.singletonMap("_id", Sort.Direction.ASC)); } if (StringUtils.isNotBlank(pre)) { build.setQuery(pre); } return build; }
**RequestPagingOverReader**** **Http类的数据读取,支持增量、全量,失败后偏移位置记录重试
private ItemReader getRequestItemReader(Object startAfter, final org.apache.log4j.Logger logger, DatasourceDO rds, String offsetF) { RequestPagingOverReader build = new RequestPagingOverReader(logger); build.setName(PAGING_READER); build.setTargetType(Document.class); build.setTemplate(restTemplate); if (startAfter != null) { build.setPrevious((Map<String, Object>) startAfter); } if (StringUtils.isNotBlank(offsetF)) { build.setOffsetF(offsetF); } if (PAGE == rds.getResultType() && rds.getParams() != null && rds.getParams().stream().anyMatch(it -> it != null && it.getType() == ParameterTypeEnum.DYNAMIC && StringUtils.isNotBlank(it.getValue()) && it.getValue().contains("++"))) { build.setIsPage(true); } build.setRds(rds); return build; }
以上三种reader主要做的三个操作:
1、执行前的open,获取偏移量信息
2、分页读取数据,每一次查询读取的数据返回为一个Iterator<T>或者List<T>
3、执行完的close,进行资源关闭,重置部分参数信息
5.3.2 构建Processor
ItemProcessor processor = processorBuilder.processorBuilder(dagNode, cols);
dagNode任务处理流程的有向无环图,processor阶段不会执行写入操作,但是会做写入前的最后准备工作,进行数据转置。
cols在进行writer前需要进行数据类型转换、默认值等信息填充的库表配置信息
主要实现一个ItemProcessor<I,O>接口,调用DealItemProcess.governItemToMongo(dagNode, cols)中的静态方法进行处理。
public ItemProcessor<Document, Document> processorBuilder(DagNode dagNode, List<ColumnDTO> cols) { return DealItemProcess.governItemToMongo(dagNode, cols); }
调用递归方法进行数据处理后再进行写入前toMongoDocument(cols, document)的数据准备。
public static ItemProcessor<Document, Document> governItemToMongo(DagNode dagNode, List<ColumnDTO> cols) { return item -> { Document document = recursionExecNode(dagNode, item); if (document == null) { return null; } // 对数据字段进行过滤 return toMongoDocument(cols, document); }; }
执行阶段通过有向无环图按序执行DagService.execDagNode(dagNode.getData(), dagNode.getType(), document, null);数据处理。
/** * 递归执行除了输入输出组件 * * @param dagNode * @param document * @return * @throws Exception */ private static Document recursionExecNode(DagNode dagNode, Document document) throws Exception { // 依次递进,执行当前的节点中发现依赖了别的节点,则先执行别的节点 // 1 查看是否依赖其他节点的执行 List<DagNode> nodes = dagNode.getNodes(); // 2 存在依赖其他节点则继续向下查找 if (nodes != null && !nodes.isEmpty()) { for (DagNode node : nodes) { document = recursionExecNode(node, document); } } if (dagNode.getType().equals(TaskNodeEnum.DATA_INPUT.getEnName()) || dagNode.getType().equals(TaskNodeEnum.DATA_COLLECT.getEnName()) || dagNode.getType().equals(TaskNodeEnum.DATA_OUTPUT.getEnName())) { return document; } // 主要数据处理 document = DagService.execDagNode(dagNode.getData(), dagNode.getType(), document, null); return document; }
根据任务配置的执行,目前支持数据清洗、脱敏、转换、行拆分、列拆分、过滤组件。
public static Document execDagNode(Object dagNode, String typeStr, Document document, String symbol) { TaskNodeEnum type = TaskNodeEnum.getEnumByEnName(typeStr); switch (type) { case DATA_CLEAN: return DataCleanService.executeDataClean(dagNode, document); case DATA_DESENSITISE: return DataEncryptService.excuteDataEncrypt(dagNode, document); case DATA_CONVERT: return DataConvertService.executeDataConvert(dagNode, document); case DATA_SPLIT: return DataSplitService.executeDataSplit(dagNode, document); case DATA_QUERY: return DataQueryFilterService.executeDataQuery(dagNode, document); case DATA_FILTER: // todo 去重组件需要单独处理 case DATA_UNION: // todo 归并组件需要单独处理 case DATA_EXPLODE: DataExplodeService.executeDataExplode(dagNode, document, symbol); return null; case DATA_COLLECT: case DATA_INPUT: case DATA_OUTPUT: return document; default: throw new BizException("暂不支持的数据处理规则:" + JSON.toJSONString(dagNode)); } }
5.3.3 构建Writer
MongoItemWriter writer = processorBuilder.writerBuilder(output);
output输出源信息,根据配置得知写入模式,进行相应处理
构建Writer主要实现ItemWriter<T>接口。
根据需求目前支持两种**writer**
if (HTTP.equals(type)) { logger.error("暂不支持与http进行数据交换"); throw new BizException("暂不支持与http进行数据交换"); } else if (MONGO.equals(type)) { MongoTemplate template = LoadCacheUtil.getMongoTemplate(datasourceDO); MongoWriter transItemMongoWriter = new MongoWriter(output); transItemMongoWriter.setTemplate(template); transItemMongoWriter.setCollection(output.getCode()); return transItemMongoWriter; } else if (MYSQL.equals(type)) { MysqlWriter mysqlWriter = new MysqlWriter(output); // 设置未匹配上也持续进行更新,不中断操作 mysqlWriter.setAssertUpdates(false); HikariDataSource hikariDataSource = LoadCacheUtil.getConnection(datasourceDO); mysqlWriter.setDataSource(hikariDataSource); mysqlWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()); mysqlWriter.setItemPreparedStatementSetter((item, ps) -> { List<ColumnDTO> fieldMap = output.getFieldMap().stream() .filter(it -> StringUtils.isNotBlank(it.getSourceCode())).collect(Collectors.toList()); JSONObject jsonObject = DealItemProcess.toMysqlJSONObject(fieldMap, (Document) item); // insert、replace into指定code、values,进行update时'set(code=?)'和'values(?)'是一样 int size = fieldMap.size(); setCodeValue(ps, fieldMap, jsonObject, size); // update操作需要指定where if (output.getScope() == 3) { setWhereValue(output, ps, jsonObject, size); } }); return mysqlWriter; }
MongoWritermongo写入,支持覆盖、更新插入、纯更新
public MongoWriter(DataOutputDTO output) { this.codes = output.getCodes(); this.scope = output.getScope(); this.collection = output.getTableCode(); this.updateExculdeField = output.getCols().stream().filter(it -> // 没有映射关系的不做更新,默认值需要更新 StringUtils.isBlank(it.getSourceCode()) && it.getSpecialValue() == null).map(ColumnDTO::getCode) .collect(Collectors.toList()); }
交换任务更新字段字段不做要求
public MongoWriter(ExchangeOutputDTO exchangeOutput) { this.codes = exchangeOutput.getCodes(); this.scope = exchangeOutput.getScope(); this.collection = exchangeOutput.getCode(); this.updateExculdeField = exchangeOutput.getFieldMap().stream().filter(it -> // 没有映射关系的不做更新 StringUtils.isBlank(it.getSourceCode())).map(ColumnDTO::getCode) .collect(Collectors.toList()); }
重写doWrite(List<? extends T> items方法,根据配置信息不同使用template进行数据写入处理
@Override protected void doWrite(List items) { MongoOperations template = super.getTemplate(); MongoCollection<Document> templateCollection = template.getCollection(collection); if (scope == 0) { if (symbol == 0 && template.getCollectionNames().contains(collection)) { // todo drop 删除了collection ; 暂时改为deleteMany删除数据,templateCollection.drop(); templateCollection.deleteMany(new BsonDocument()); this.symbol = 1; } template.insert(items, collection); } else if (scope == 2) { if (templateCollection.estimatedDocumentCount() == 0) { this.symbol = 1; } if (symbol == 1) { template.insert(items, collection); } else { upsertData(items, templateCollection); } } else if (scope == 3) { // 对collection仅进行更新 updateDate(items, template); } else { template.insert(items, collection); } }
MysqlWritermysql写入,覆盖、更新插入、纯更新
主要代码块包括三个setSql(),根据不同配置信息生成不同的Sql语句进行执行。
private void init() { StringBuilder fields = new StringBuilder(); StringBuilder mark = new StringBuilder(); StringBuilder update = new StringBuilder(); // 如果没有映射字段则不做preparedStatementSetter的预编译 List<ColumnDTO> temp = fieldMap.stream().filter(it -> StringUtils.isNotBlank(it.getSourceCode())).collect(Collectors.toList()); for (int i = 0; i < temp.size(); i++) { ColumnDTO fieldMapDTO = temp.get(i); String code = fieldMapDTO.getCode(); update.append("`").append(code).append("`").append("=?"); fields.append("`").append(code).append("`"); mark.append("?"); if (i < temp.size() - 1) { fields.append(","); mark.append(","); update.append(","); } } StringBuilder where = new StringBuilder(); for (int i = 0; i < codes.size(); i++) { String code = codes.get(i); where.append(code).append("=? "); if (i < codes.size() - 1) { where.append(","); } } // 构建语句时需要注意是否存在映射关系 String errMessage = "数据写入失败,不存在字段映射关系"; if (scope == 1) { if (StringUtils.isBlank(fields)) { throw new BizException(errMessage); } setSql("INSERT INTO " + table + "(" + fields + ") VALUES(" + mark + ")"); } else if (scope == 2) { if (StringUtils.isBlank(fields)) { throw new BizException(errMessage); } setSql("REPLACE INTO " + table + " (" + fields + ") VALUES (" + mark + ")"); } else if (scope == 3) { if (StringUtils.isBlank(update)) { throw new BizException(errMessage); } setSql("UPDATE " + table + " SET " + update + " WHERE " + where); } }
5.3.4 监听
根据需要目前主要设置了一下五个监听器。
- ItemListener
ItemListener实现了ChunkListener, JobExecutionListener两种监听器。
功能:
1、主要监听数据量的变化和数据处理发生的块异常。
2、监听
Job主要执行流程,以及进行任务的基本信息输出,任务成功或者失败后的偏移字段位置重定位。
- StepListener
StepListener实现了StepExecutionListener一种监听器。
功能:
1、
Step执行前将偏移字段位置告知给Reader,以实现增量读取数据。
2、
Step执行完成后进行状态变更。
- ReaderListener
ReaderListener实现了ItemReadListener接口。
功能:
1、数据读取出错时进行错误提示。
- ProcessListener
ProcessListener实现了ItemProcessListener接口。
功能:
1、数据处理出错时进行错误提示。
- WirterListener
WirterListener实现了ItemWriteListener接口。
功能:
1、数据写入出错时进行错误提示。



👍
😳 先评论一下再说.
加个人气
👍 插眼
感谢分享