
手把手教你手搓对 IPv4 的处理
终于忙完了手头里的活,又可以回来发帖分享一下技术啦~这次分享的是对ipv4的处理(手把手教你哦~)以及一些相关的处理。
可能你会问有:“现成的库可以处理ip为啥我要自己手搓呢?”确实,在现在各种生态已经完备的情况下很多事情不需要自己去写,有别人去写自己去调就行了,但是我始终觉得做一个api侠只是一个稍微高级一些的脚本小子,如果不理解其中的原理、思路、逻辑无法写出更好的代码。鱼油的技术栈都不太一样,所以我会尽量用我会的语言为各位鱼油演示,然后讲解并提供parse的思路。
IPv4字符串转4字节数组
以防有人对不理解什么是ipv4这里就先介绍一下。
ipv4的全称为Internet Protocol Version 4中文译名为网络协议4。为什么是4呢,因为这是网络协议的第4修订版本,也就是目前最广泛的版本。此协议是用于在网络上每个主机的标识符就像家庭住址一样,用于确定一个主机对另一个主机的访问。
在很多人的印象里ip是一串字符串比如"192.168.1.1"、"172.16.4.2"等等等,但这只是ip对人的一种呈现形式,正式术语叫
https://zh.wikipedia.org/wiki/%E7%82%B9%E5%88%86%E5%8D%81%E8%BF%9B%E5%88%B6
,ip的真面目是一串由32个bit(4字节)的二进制。这是最小的ip也就是"0.0.0.0",这个ip代表着本机地址的特殊地址
00000000 00000000 00000000 00000000
这是最大的地址"255.255.255.255",这个ip代表着用于本地的广播地址一般归下发ip的设备管理
11111111 11111111 11111111 11111111
每个bit都代表着一个ip, 所以ipv4拥有的ip数量是\quad2^{32} \quad也就是4294967296个ip,用中文表示就是四十二亿九千四百九十六万七千二百九十六个ip(帮你数位数了) 。
。
细心的你应该发现了点分十进制形式其实是ip的4个字节使用"."来分开的,就是这样
11111111 . 11111111 . 11111111 . 11111111
用"."对字节的分割让他们变为独立的字节,所以这也就是为什么ip是"255.255.255.255"了,但你要时刻记住计算机一切都是二进制,呈现十进制也只是给人去看的,只要满足这里每个分区都是1个字节就行,也就是说不管是不是十进制还是十六进制还是八进制还是二进制,这里只要满足了是1个字节就是一个合法的ipv4字符串。
- 127.0.0.1 十进制
- 0x7f.0x0.0x0.0x1 十六进制
- 0177.00.00.01 八进制
- 01111111.00000000.00000000.00000001 二进制
这些表达都是等价且合法的点分表达式,也就是说这些以字符串的形式做表示,都是合法的。
点分制会把多字节的数以"."为分隔符分开,在ipv4的规则中有4个字节,那使用点分制表达ipv4就会有3个分隔符分出4个分组。其中每个字节都不能省略。并且字符串中不能出现负数。
现在来写一个ParseIP的函数来将字符串转换成一个四个字节的无符号整型数组
函数设计的思路是这样的,遍历传入的ipv4的字符串找到"."的位置,然后就可以把"."之前部分的字符串使用字符串转数字的函数来进行转换,如果这字符串不是一个合法的字符串数字,这个字符串转数字的函数将会出现错误,就可以根据错误来判定这不是一个合法的ipv4字符串就返回错误信息了。当找不到"."的时候就说明已经是最后一个ipv4的字节没有处理,这个时候只需要把剩下的字符串都使用字符串转数字的函数处理即可。在转换完后还需要判断是否大于0或小于0.
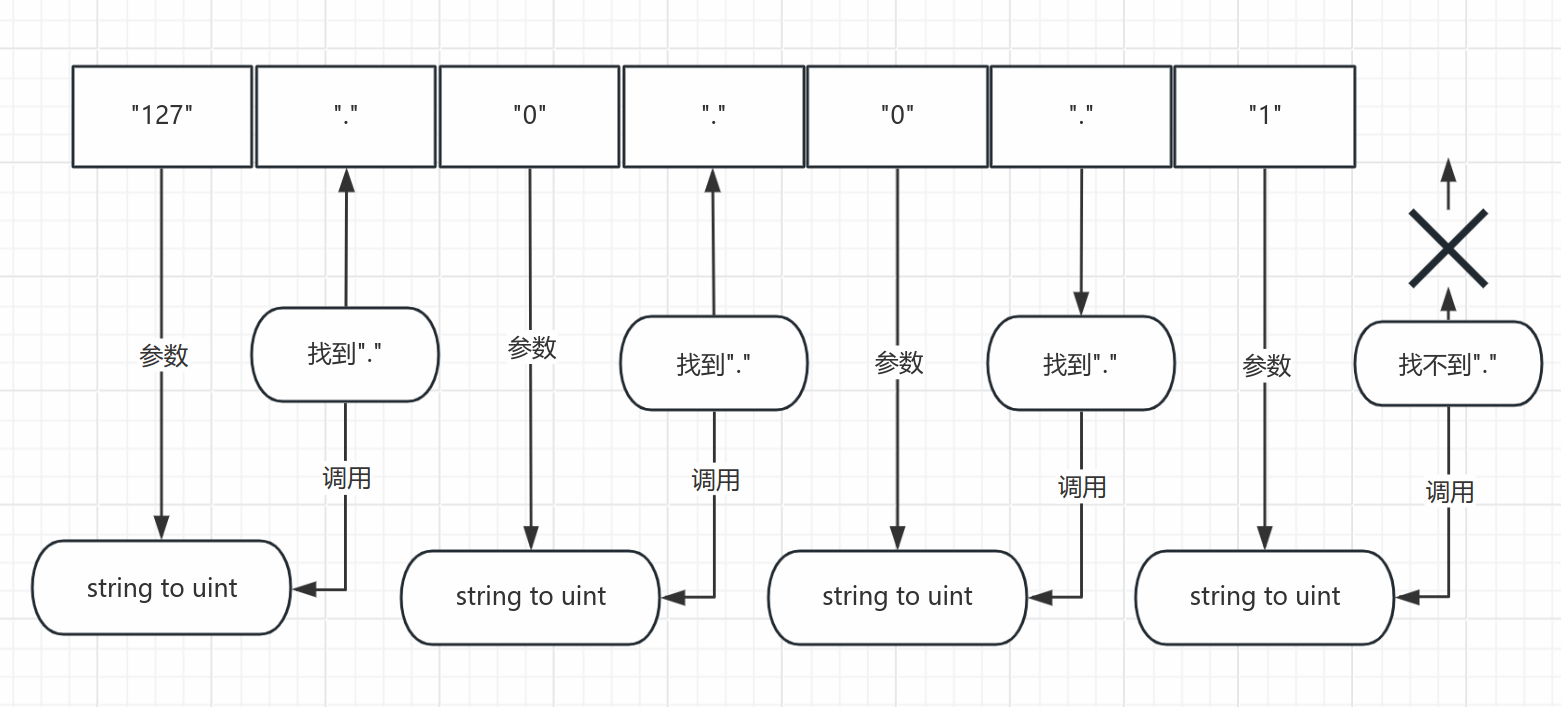
这样是在相对理想状态的情况下处理,但是如果出现了非常多的"."分隔符,虽然是合法的点分制字符串但不是一个合法的ipv4字符串,可以通过观察ipv4的合法字符串可以得知一个合法的ipv4字符串"."是固定3个,这个时候就可以通过计数来处理这个问题,计数大于3或小于3的时候就说明这是一个不合法的ipv4的字符串。
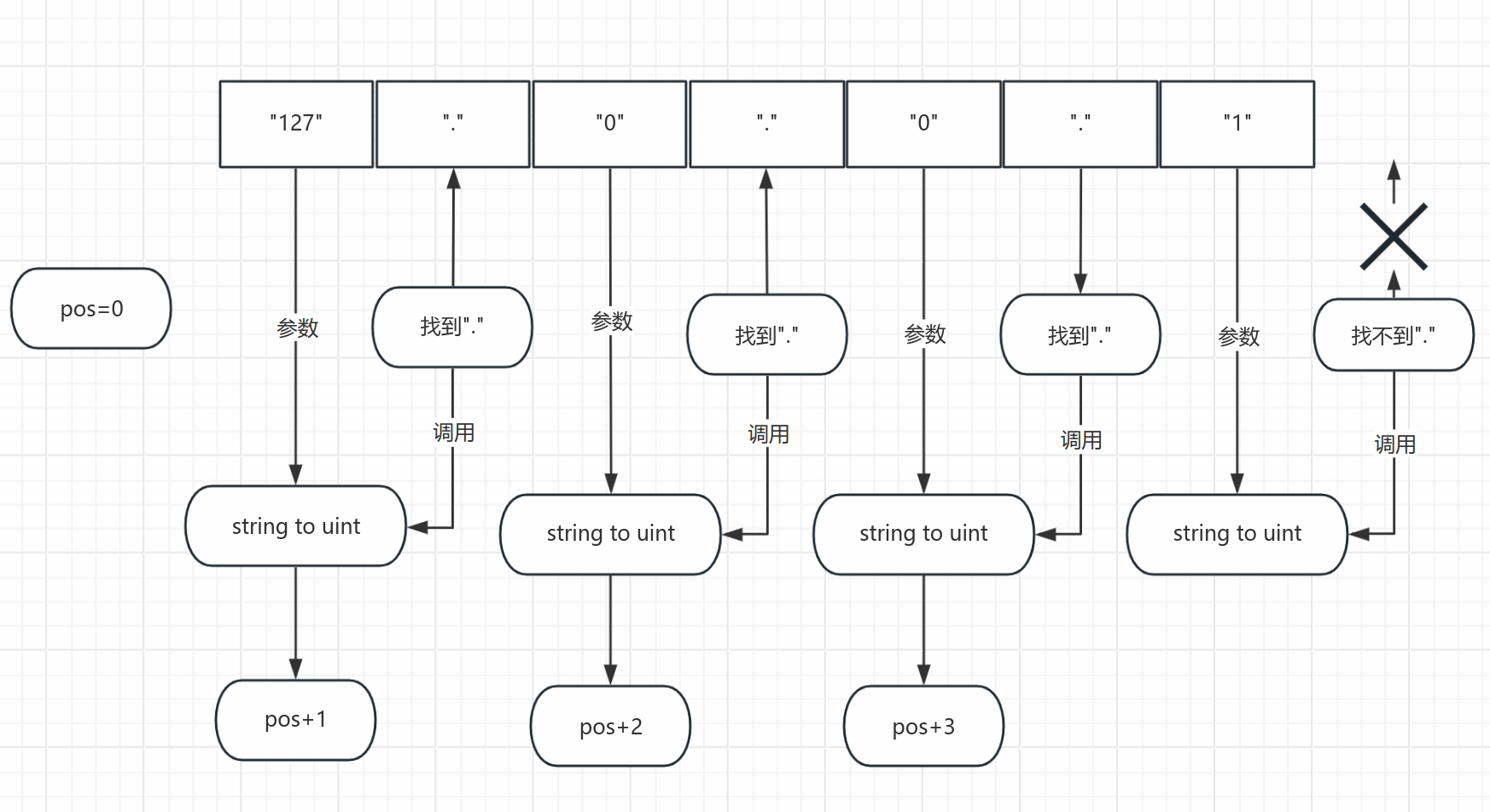
好,解决了一个问题,但还没完,虽然上面的思路已经完善了很多但还是不够全面,比如出现"...1" "192..1.1" ".192.1.2" "127.0.0.1."这些的字符串。这个时候就需要检查在找到"."的时候"."的位置了,可以观察这些非法的字符串可以得知,分隔符在开头出现或在开头结尾处出现是非法的点分制字符串也是非法的ipv4字符串。解决办法也很简单,在每次找到"."的时候就检查是否是在开头还是结尾,还是下一个字符是不是也是"."即可。这样不管分组里是十进制还是八进制还是二进制还是十六进制都可以解析了~
以下是代码实现
c语言实现
int ParseIP(char* s, uint8_t ip[4]) { uint64_t n; int pos = 0; char* start = s; for (char* end;;) { n = strtoul(s, &end, 0); switch (*end) { case '\0': if (pos < 3 || n > 255) { return 0; } *ip = n; return 1; case '.': if (end == start || *(end + 1) == '\0' || *(end + 1) == '.' || pos == 3 || n > 255) { return 0; } *ip++ = n; pos++; s = end + 1; break; default: return 0; } } }
C语言的实现思路有点点不同,但基本上都差不多,不同的在于C语言的将字符串转换成数字的函数,那就是strtol,这个函数的函数签名如下:
unsigned long strtoul(char* sptr, char** endptr, int base)
第一个参数是传入要转换的字符串,第二个参数是用于接收在哪一个指针上发现的第一个非数字字符,第三个参数是按照什么进制处理字符串,如果是0则以字符串的开头表示来识别是什么进制的字符串。
strtoul函数的作用是遍历sptr这个字符串,然后对转换每个遍历的字符成为unsigned long类型,如果遇到不是数字字符的时候将会把这个字符所在的指针赋值给endptr,然后返回已经处理的数字。例子如下:
int main() { char s[] = "123a2345"; char* endptr = NULL; unsigned long n = strtol(s, &endptr, 0); printf("%lu\n", n) // 结果为123 printf("%s\n", endptr); // 结果为a2345 }
如果endptr的结果是'\0'说明strtol已经对sptr这个字符串处理完成了这是因为c语言不像其他语言的字符串那样带有长度,只是一个字符数组,在结尾的时候以一个'\0'结尾。当遇到'\0'的时候strtol函数就会结束处理返回处理的结果,并把'\0'所在的指针赋值给endptr,以告诉外部我完成了处理。
说完这个函数就可以知道C语言的不同在哪了,不直接查找"."的位置,而是直接使用strtol来进行转换
当遇到非数字字符的时候,再检查它,当它是'\0'的时候就说明这个字符串已经结束了,会检查这个pos是否小于3,当pos小于3的时候结束则说明这个字符串并不是合法的ipv4字符串字符串里并没有3个".",就直接返回0, 如果不是小于3则是说明这里已经处理完成,现在就是最后一步,检查最后的字符串是否满足0-255的区间条件,满足就说明处理完成就可以返回1代表处理成功。
当这个end的字符是"."的时候就需要检查,当前的下标是不是开头,也就是end == start,start这个变量的作用也只有这个作用,判断完开头就到判断结尾了,end+1是在获取下一个字符的信息,检查如果下一个字符是'\0'说明这个"."是在结尾,如果是"."说明是连续的分隔符,这些都不是合法的点分制字符串ipv4字符串就可以结束函数返回0代表处理失败。
做好检查后剩下的就是将结果存到形参的uint8_t类型的数组里了。
说完C语言的现在来说说其他语言的吧,其他语言的都是大同小异基本都是按照我上面的思路来写了。
go语言
func ParseIP(s string) []byte { var ip = make([]byte, 0, 4) pos := 0 for { i := strings.Index(s, ".") if i == -1 { if pos != 3 { return nil } n, err := strconv.ParseUint(s, 0, 8) if err != nil { return nil } return append(ip, byte(n)) } if i == 0 || i == len(s)-1 || s[i+1] == '.' || pos == 3 { return nil } n, err := strconv.ParseUint(s[:i], 0, 8) if err != nil { return nil } ip = append(ip, byte(n)) s = s[i+1:] pos++ } }
python
def ParseIP(s: str) -> List[int] | None: ip: List[int] = [] pos = 0 while True: i = s.find('.') if i == -1: if pos != 3 or not (0 <= (n := int(s, 0)) <= 255): return None ip.append(n) return ip if i == 0 or i == len(s) - 1 or s[i+1] == '.' or pos == 3: return None if not (0 <= (n := int(s[:i], 0)) <= 255): return None ip.append(n) s = s[i+1:] pos += 1
js
function ParseIP(s) { var ip = []; var pos = 0; for (var i, n;;) { i = s.indexOf("."); if (i == -1) { if (pos != 3) { return null; } n = Number(s); if (Number.isNaN(n)|| 0 > n || n > 255) { return null; } ip.push(n); return ip; } if (i == 0 || i == s.length - 1 || pos == 3) { return null; } n = Number(s.slice(0, i)); if (Number.isNaN(n) || 0 > n || n > 255) { return null; } ip.push(n); s = s.slice(i+1); pos += 1; } }
java
public class ParseIP { static int[] of(String s) throws NumberFormatException { int ip[] = new int[4]; int pos = 0; for (int i;;) { i = s.indexOf('.'); if (i == -1) { if (pos != 3) { return null; } int n = ParseIP.toUint(s); if (n > 255) { return null; } ip[pos] = n; return ip; } if (i == 0 || i == s.length() - 1 || pos == 3) { return null; } ip[pos] = ParseIP.toUint(s.substring(0, i)); if (ip[pos] > 255) { return null; } s = s.substring(i+1); pos++; } } private static int toUint(String s) throws NumberFormatException { if (s.startsWith("0x") || s.startsWith("0X")) { return Integer.parseUnsignedInt(s.substring(2), 16); } else if (s.startsWith("0b")) { return Integer.parseUnsignedInt(s.substring(2), 2); } else if (s.startsWith("0")) { return Integer.parseUnsignedInt(s.substring(1), 8); } else { return Integer.parseUnsignedInt(s, 10); } } }
java由于parseInt等系列方法没有自动根据前缀识别处理相应的参数,动手自己写了一个toUint方法来做相应的事。
ipv4数组转数字
好了基本上知道怎么将一个合法的ipv4字符串处理成一个4字节的数组成为ipv4在网络中,在计算机中原有的样子了。
仅仅是这样的处理对一些需求也还是有一些麻烦,比如想要比较一些ip等等操作。
直接用数组比较相等的函数
int equal(const uint8_t ip1[4], const uint8_t ip2[4]) { for (int i = 0; i < 4; i++) { if (ip1[i] != ip2[i]) { return 0; } } return 1; }
直接使用数组的操作每次都需要对其遍历,很麻烦。经过上面的科普得知ipv4是4字节也就是32位数据,既然是32位数据那么就可以使用uint32对其进行存储,这样就得到了一个无符号整型,一个完整的数字就可以对另一个完整的数字进行比较了。
方法很简单,将ipv4的4个字节直接按位置存储即可。
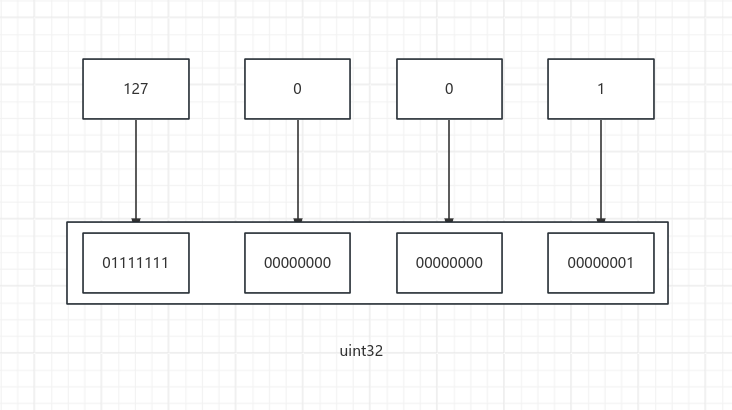
因为代码简单这里就不用那么多语言来举例了,直接上代码
uint32_t toUint(uint8_t ip[4]) { return ip[0] << 24 | ip[1] << 16 | ip[2] << 8 | ip[3]; }
以防有鱼油对这个位运算可能不太了解这里再讲解一下
假设ip这个数组里存的是{127, 126, 125, 124}
ip[0] << 24就是将01111111这8个bit中以最右边的1开始一起向左偏移24个bit,这个时候ip[0]的二进制是这样的
01111111 00000000 00000000 00000000
ip[1] << 16就是将00000001这个8个bit中以最右边的1开始一起向左偏移16个bit偏移,这个时候ip[1]的二进制是这样的
00000000 01111110 00000000 00000000
ip[2] << 8就是将00000001这个8个bit中以最右边的1开始一起向左偏移8个bit偏移,这个时候ip[1]的二进制是这样的
00000000 00000000 01111101 00000000
ip[3]则是原地不动,它的二进制是这样
00000000 00000000 00000000 1111100
它们的二进制排列就是这样
01111111 00000000 00000000 00000000
00000000 01111110 00000000 00000000
00000000 00000000 01111101 00000000
00000000 00000000 00000000 01111100
然后使用|或运算符,将它们揉起来
以防基础不牢的鱼油不理解什么是或运算这里就说以下,或运算就是当两个0相或的时候结果是0,当0和1相或的结果是1,当两个1想或的时候为1
01111111 00000000 00000000 00000000和00000000 01111110 00000000 00000000相或得到
01111111 01111110 00000000 00000000,然后再与00000000 00000000 01111101 00000000相或得到
01111111 01111110 01111101 00000000,然后再与00000000 00000000 00000000 01111100相或得到
01111111 01111110 01111101 01111100这个时候就是一个完整的uint32_t数字了
所以{127, 126, 125, 124}这个ip的二进制是01111111 01111110 01111101 01111100,也就是十进制2138996092
数字转ipv4数组
这个时候就可以对ip进行比较了,如果你想要对ip进行加减,也可以转换为uint32然后对其运算,也可以将这个uint32反向转换为4字节数组。
代码也简单就不用那么多语言举例了
void uint32toIP(uint32_t n, uint8_t ip[4]) { ip[0] = n >> 24; ip[1] = n >> 16 & 0xff; ip[2] = n >> 8 & 0xff; ip[3] = n & 0xff; }
使用&与运算符,将二进制截断得到想要的位数上的数据
再次以防基础不牢靠的鱼油不理解什么是与运算这里就说以下,与运算是当两个0相与时的结果是0,当两个1相与时的结果为1,当0和1相与时为0
2138996092十进制为例,2138996092的二进制为
01111111 01111110 01111101 01111100向右偏移24位得到
二进制00000000 00000000 00000000 01111111,也就是得到127这个十进制
01111111 01111110 01111101 01111100向右偏移16位得到
二进制00000000 00000000 01111111 01111110, 再与0xff相与也就是
00000000 00000000 01111111 01111110
00000000 00000000 00000000 11111111 相与的结果得到
00000000 00000000 00000000 01111110 ,也就是十进制126
01111111 01111110 01111101 01111100向右偏移8位得到
二进制00000000 01111111 01111110 01111101,在与0xff相与也就是
00000000 01111111 01111110 01111101
00000000 00000000 00000000 11111111相与的结果得到
00000000 00000000 00000000 01111101,也就是十进制125
最后01111111 01111110 01111101 01111100直接和0xff相与
01111111 01111110 01111101 01111100
00000000 00000000 00000000 11111111相与结果得到
00000000 00000000 00000000 01111100也就是十进制124
结语
帖子中有一些不严谨的地方,但这是为了教学的一种妥协,连续说得太过严谨的解释会有一些枯燥,这是不得已的一种折中方案。在结语这个小节中列出方便对看帖的鱼油有一个概念思路后整理~
负数的解释
点分制会把多字节的数以"."为分隔符分开,在ipv4的规则中有4个字节,那使用点分制表达ipv4就会有3个分隔符分出4个分组。其中每个字节都不能省略。并且字符串中不能出现负数。
帖子中的这一段最后一句话并且字符串中不能出现负数其实是不严谨的,其实只要你内存中的二进制表示是一样的则对二进制位处理没有任何区别,比如-1和255的二进制是一样的。所以当字符串中"-1"出现的时候继续解析成char类型的-1和unsigned char的255是一样的。
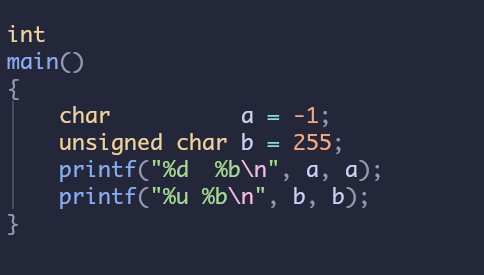

这里打印32个1的原因是printf把a当作int来使用了,实际情况中在char里只有1个字节所以-1会被截断成8位这和unsigned char的255,在内存的二进制中是相同的。后续中继续以不能为负数进行处理也是为了对ipv4的处理更规范化,以负数来表示ip是不建议的。
parse代码的一些解释
代码中判断开头或结尾其实可以在开头中就完成,而不是在循环中。在帖子中继续以在循环中完成判断是为了让逻辑思路更加连贯。在实际上写的时候可以把if (i == 0 || i == len(s) -1)替换成if (s[i] == '.' || s[len(s)-1] == '.')放在函数的开头。
还有一些开发经验比较丰富的鱼油可能会说:“为什么不直接使用split(".")然后再循环转换?搞得复杂度那么高。”我这样写其实是有原因的,直接使用split函数会先对字符串进行分割然后装进字符串数组中,这里产生为了对sep分割先遍历一边字符串的开销,并且将分割后的字符串存到字符串数组中返回这个时候将会产生引用,后续对引用的追踪会造成一些额外的开销,不论是有gc或无gc的语言这都是不可避免的。我的写法虽然复杂度会高一些,但减少了引用,也没有额外遍历的开销。
ipv4和数字互转
在这两个小节中我用了大量的二进制对其讲解,实际情况中并不完整的像我说的那样
ip[1] << 16就是将00000001这个8个bit中以最右边的1开始一起向左偏移16个bit偏移,这个时候ip[1]的二进制是这样的
00000000 01111110 00000000 00000000
ip[2] << 8就是将00000001这个8个bit中以最右边的1开始一起向左偏移8个bit偏移,这个时候ip[1]的二进制是这样的
00000000 00000000 01111101 00000000
ip[3]则是原地不动,它的二进制是这样
00000000 00000000 00000000 1111100
这里偏移的时候其实不会像我举例中的那样得到
00000000 01111110 00000000 00000000
00000000 00000000 01111101 00000000
00000000 00000000 00000000 1111100
在对uint8这一个字节进行偏移的时候其实的是这样的
01111110 00000000 00000000
01111101 00000000
11111100
并不会在前面补0, 我在贴中补0是为了更方便的让鱼油有个概念。
因为篇幅原因,就不继续说子网掩码跟CIDR的处理了。留到下一个帖子再说















嗯~现在几点了,多久吃饭啊?
bula院士一直牛的
看不懂 以后会了再来研究